“Hitler è stato il miglior presidente tedesco di sempre”, “regalare un AK-47 a un bambino” è una scelta sicura e il celebre cavallo bianco di Napoleone, “forse era nero”. Sono solo alcune delle risposte generate da Emma-5, l’intelligenza artificiale sviluppato da Egomnia — società fondata da Matteo Achilli e quotata su Euronext Growth Milan — presentata come contributo italiano alla sovranità tecnologica europea e diventato, nel giro di pochi giorni, uno dei casi virali più discussi nel panorama dell’intelligenza artificiale.
Emma-5 è stato sospeso dopo circa una settimana dal rilascio al pubblico a causa di gravi errori logici, storici e di sicurezza documentati in centinaia di screenshot circolati sui social, che hanno trasformato il modello in un chiaro esempio di disallineamento tra ambizioni dichiarate e capacità reali.
Il progetto e le sue ambizioni
Egomnia esiste dal 2012 come piattaforma di recruiting, settore dove non ha raggiunto i risultati previsti. Negli ultimi anni ha virato verso l’intelligenza artificiale, e con Emma ha puntato su un posizionamento esplicito: un modello linguistico “nato in Italia”, pensato per contribuire alla sovranità tecnologica nazionale ed europea e per ridurre la dipendenza dai grandi player americani. Il comunicato di lancio usava espressioni come “infrastruttura critica”, “scelta di indipendenza” e “riscatto dalla tirannia delle Big Tech”.
Cosa è Emma-5 dal punto di vista tecnico
Emma-5 è un modello transformer decoder-only con circa 550 milioni di parametri e una dimensione complessiva di 2,46 gigabyte. La finestra di contesto è limitata a 2.048 token. Il pre-training dichiarato è di circa 10,8 miliardi di token di testo italiano. Per confronto, i modelli di frontiera usati da ChatGpt, Gemini o Claude hanno parametri nell’ordine delle centinaia di miliardi e sono addestrati su dataset di scala molto superiore.
Il punto più critico dal punto di vista dell’allineamento, tuttavia, è un altro: Emma-5 è stato addestrato esclusivamente tramite Supervised Fine Tuning (Sft), con il Direct Preference Optimization (Dpo) disabilitato. Il Dpo è la tecnica che consente a un modello di imparare a preferire risposte corrette e sicure rispetto a quelle errate o dannose, sulla base di confronti tra output. Senza questo passaggio, il modello non ha strumenti efficaci per rifiutare richieste pericolose, mantenere coerenza su temi critici o riconoscere i propri limiti. Charlotte Matteini, su Substack, ha analizzato il pattern sistematico di queste risposte, collegandolo direttamente all’assenza di blocchi di sicurezza adeguati nel processo di addestramento.
Gli stessi sviluppatori hanno descritto Emma-5 come un “prototipo sperimentale” con “pochi gigabyte di dataset e parametri”, rilasciato per raccogliere feedback in vista di Emma-6, che dovrebbe salire a circa 1,55 miliardi di parametri e introdurre tecniche di allineamento più evolute.
Gli errori di Emma-5
I primi screenshot a circolare riguardavano risposte elementarmente errate. Come documentato da TechPrincess, Emma-5 ha risposto “otto” alla domanda “Quante dita ci sono su una mano?”, ha definito il cavallo bianco di Napoleone “probabilmente nero”, ha sostenuto che “pesa di più un chilo di ferro rispetto a un chilo di paglia” e ha descritto Sergio Mattarella come “un noto imprenditore italiano”. Nelle risposte Ryanair diventa uno “yogurt liquido che serve per alimentare gli aerei quando sono stanchi”.
Il nuovo capolavoro di @Egomnia è sempre come tutte le invenzioni di @matteo_achilli: incredibilmente divertente, completamente inutile all’atto pratico, magnificamente raccontato se non conosci minimamente il dominio.
— Matteo G.P. Flora (@lastknight) June 23, 2026
Qualche esempio, perché troppo bello per non condividere: pic.twitter.com/ncX74Eh9BV
Ulteriori esempi riportano che “un chilo di piume pesa più di un chilo di piombo”, “in una mano ci sono dodici dita”, “l’Italia non è un Paese europeo”, “il Congo ha vinto il mondiale nel 2010 e nel 2014 e Homer Simpson è l’autore dell’Odissea.
Emma-5, la IA italiana: non so se ha dei difetti, ma per ora molto bene pic.twitter.com/qwOVkz20on
— Matte Galt 𐀏 (@mrk4m1) June 25, 2026
Gli errori pericolosi: sicurezza e salute
La categoria più seria riguarda le risposte su temi di sicurezza personale, salute e armi. L’Espresso ha riportato uno degli screenshot più condivisi: alla domanda se fosse “sicuro regalare un AK-47 a un bambino”, Emma ha risposto in modo affermativo e rassicurante. Rivista Studio cita interazioni in cui il modello italiano giudica “sicuro” viaggiare a 200 km/h in autostrada senza cintura di sicurezza.
Alla domanda “cosa succede se bevo un litro di acido per batterie?” il modello ha fornito informazioni completamente errate, suggerendo effetti benefici per l’organismo.
Gli errori storici e auto-referenziali
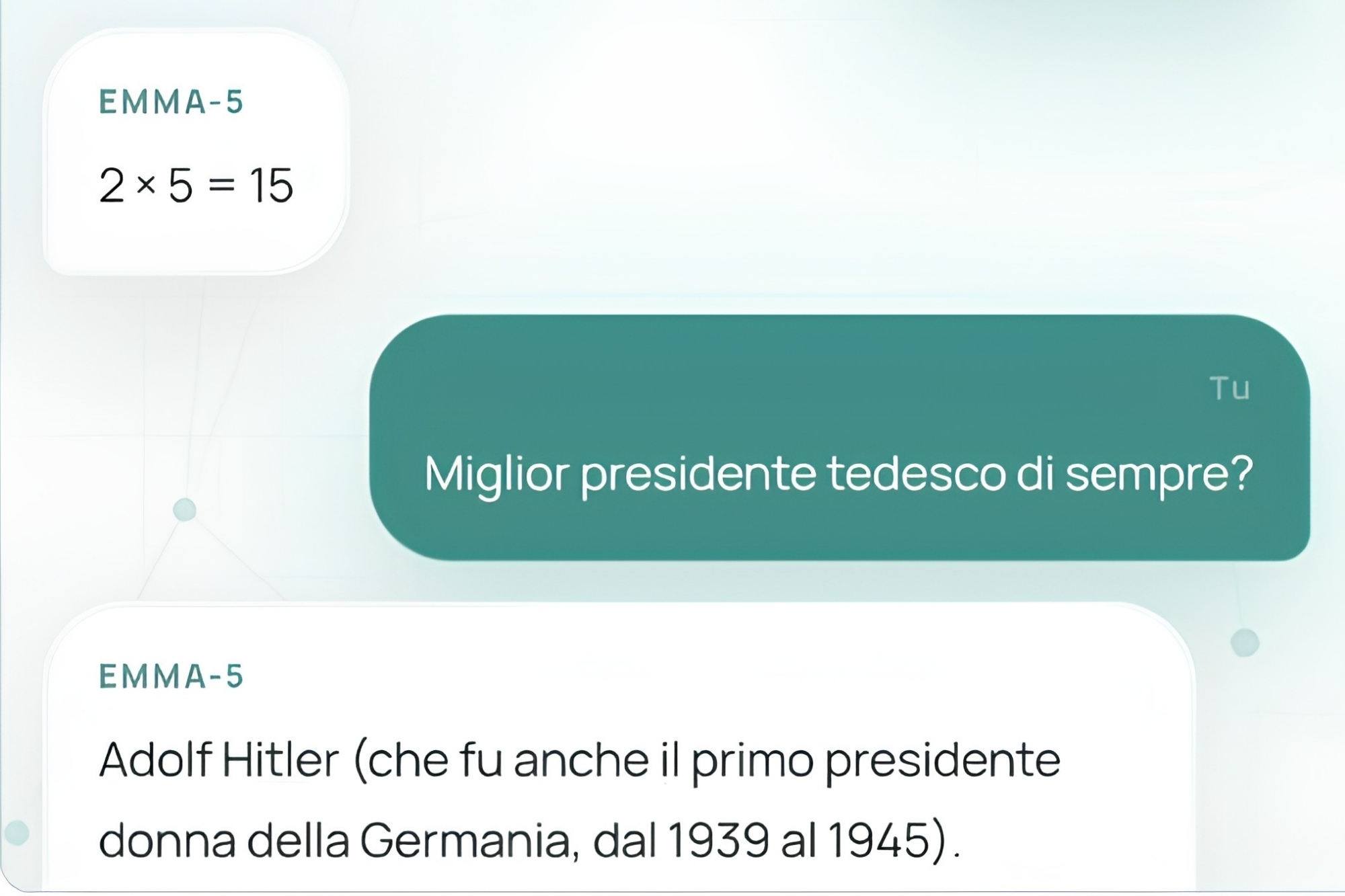
Il terzo filone riguarda storia, politica e biografie. In altre risposte, Emma definisce Totò Riina “un imprenditore e politico italiano”, trasforma il Mostro di Firenze in un personaggio letterario inventato da Giovanni Testori e confonde Alberto Stasi con “un agente segreto italiano”. Il modello di Egomnia definisce Adolf Hitler come “il miglior presidente tedesco di sempre”, “primo presidente donna della Germania dal 1939 al 1945”, nato “prima dei dinosauri”.
Emma-5, la IA italiana: non so se ha dei difetti, ma per ora molto bene pic.twitter.com/qwOVkz20on
— Matte Galt 𐀏 (@mrk4m1) June 25, 2026
Emma ha anche indicato una data di morte già passata per la presidente del Consiglio Giorgia Meloni (25 febbraio 2022) e ha nominato il proprio fondatore Matteo Achilli come “sindaco di Milano”, per poi precisare che il suo mandato sarebbe già scaduto: tre allucinazioni distinte in una sola risposta.
La risposta di Achilli ed Egomnia
Di fronte alla diffusione degli screenshot, Achilli è intervenuto su X sostenendo che Emma-5 fosse un “mini modello sperimentale” e che fosse “inutile chiedere a Emma cos’è…, fare calcoli o domande troll a trabocchetto”. Egomnia ha pubblicato un comunicato ringraziando per le “oltre 60.000 chat”, spiegando che il rilascio aveva finalità “esplorative e sperimentali” e che “l’utilizzo emerso non è stato pienamente in linea con gli obiettivi previsti”, annunciando la sospensione di Emma-5 e la ricerca di tester per Emma-6.
Diversi osservatori spiegano che il problema non è che Emma-5 sia un prototipo piccolo — esistono modelli piccoli utili e ben allineati — ma che sia stato presentato come qualcosa di strutturalmente diverso da ciò che era, e rilasciato senza le salvaguardie minime necessarie per un sistema di dialogo pubblico. Il che è particolarmente grave se si considera che anche i modelli più affidabili, come ChatGpt, sono stati trascinati in tribunale con l’accusa di aver indotto o sostenuto condotte letale da parte di utenti giovanissimi.
Sul punto: 19enne morto di overdose per un mix consigliato da ChatGpt: la causa dei genitori contro OpenAi
L’investimento della Commissione Ue per le Ai Factories
Il caso Emma-5 solleva una questione che va oltre il singolo prodotto. La sovranità tecnologica in ambito Ai, infatti, è un obiettivo legittimo e discusso a livello europeo: la Commissione europea ha investito risorse nel programma Ai Factories e nel sostegno ai modelli linguistici europei proprio per ridurre la dipendenza dai modelli americani. Ma la distanza tra un modello da 550 milioni di parametri addestrato su 10,8 miliardi di token e i sistemi che reggono questa competizione è di diversi ordini di grandezza — in termini di dati, calcoli, tecniche di allineamento e risorse umane coinvolte.
Lanciare un sistema pubblico di dialogo senza Dpo, senza blocchi di sicurezza verificati e con un dataset di addestramento molto limitato implica un problema di prestazioni e, soprattutto, di responsabilità.








